The day your GraphQL endpoint 404s
If you were building in the “Subgraph Era,” your backend often had one quiet dependency: a hosted GraphQL endpoint that turned messy, low‑level chain data into clean entities.
Then on December 8, 2025, Alchemy Subgraphs was sunset and “all subgraph and query endpoints” were discontinued.
What a lot of teams learned (sometimes the hard way) is that indexing is not a nice-to-have analytics add-on. It’s application infrastructure. Envio’s own framing matches this: the indexer typically sits between the blockchain and your app backend, transforming raw on-chain data into the structured state you actually query
This article is a practical “whiteboard walk-through” of what broke, what people learned, and how to rebuild a common subgraph-backed feature (a token-flow feed for traders/bots) using Envio HyperIndex — with enough technical depth that an engineer can ship it, and enough intuition that a trader understands why it matters.
What subgraphs were and why the shutdown hit so many teams
A Subgraph (in the Graph ecosystem sense) is typically defined by three pieces:
subgraph.yaml: which contracts + events to index and how to map themschema.graphql: the entity model you want to querymapping code: handler logic (often AssemblyScript) that writes entities as events arrive
One detail that’s easy to forget until you go multichain: a single subgraph can index multiple contracts, but not multiple networks.
So what many teams did in practice was run N near-identical subgraphs per chain… and then stitch results together in the app.
Alchemy’s hosted Subgraphs product made that pattern feel “solved” until it wasn’t. Their deprecation notice is blunt: service sunset on Dec 8, 2025; endpoints discontinued; they pointed users to migrate to Goldsky to keep using subgraphs.
That’s the key “post-subgraph” shift: builders started treating the indexing layer like any other critical backend dependency — something you design for portability, observability, migration, rollback, and cost
Your indexer is part of your backend contract.
Envio’s description of indexers matches the real-world use: ingest blocks/tx/logs → apply deterministic logic → store structured entities that your backend can rely on.
When that layer disappears, every downstream service (alerts, dashboards, bots, portfolio views) gets weird fast.
Portability is about more than “can I redeploy the YAML.”
A migration isn’t just subgraph.yaml → something else. It’s also:
schema compatibility (“near copy paste” is the dream)handler language/runtime differences (AssemblyScript vs TypeScript/JS/ReScript)query semantics (Graph Node’s custom query conventions vs standard GraphQL engines)
Envio leans into this by explicitly documenting migration steps and by providing conversion tooling for queries when you can’t update every client immediately.
Multichain is a product feature, not “extra deployments.”
Envio’s HyperIndex is built around multichain indexing inside a single indexer, with config patterns that define a contract once and list network-specific deployments under networks.
That’s not just elegance. It reduces operational surface area: fewer deployments, fewer drift bugs, fewer “why is Arbitrum behind Base?” incidents.
Event volume is your enemy unless you filter ruthlessly.
In post-subgraph land, teams became more intentional about which events they index. Envio’s documentation highlights two especially useful primitives for this:
Wildcard indexing: index events by signature without needing a specific contract address; useful for standards like ERC‑20 transfersTopic filtering: restrict wildcard events by indexed parameters (e.g., only transfers to/from a watchlist)
That combination is basically “build a trader feed without drowning in chain noise.”
Reorgs and head latency are not theoretical.
Envio exposes knobs like rollback_on_reorg (with performance tradeoffs) in the config schema reference.
And they have dedicated discussion around “latency at the chain head,” including how configuration like unordered multichain mode can keep other chains moving even if one chain gets slow.
A small but telling example: Envio’s February 2026 update says they removed an “ordered multichain mode” because forcing global ordering across chains introduced latency and could allow one problematic chain to freeze the entire indexing process.
That’s a very “post-subgraph” kind of design decision: optimize for resilience and timeliness, and model cross-chain relationships explicitly instead of assuming a single global event order.
Practical rebuild with Envio HyperIndex
Let’s rebuild a very real “subgraph era” feature:
A token-flow feed that traders/bots use to answer:
“Which wallets are suddenly receiving (or dumping) tokens right now — across multiple chains?”
We’ll build it as an indexer that captures ERC‑20 Transfer events, but only if they involve a watchlist of addresses (exchange wallets, known whales, protocol vaults, whatever you care about).
This is a great demo because it lands for all audiences:
Traders get a clean feed + leaderboards.Builders get a backend‑grade API.Infra folks see how to keep the blast radius small.
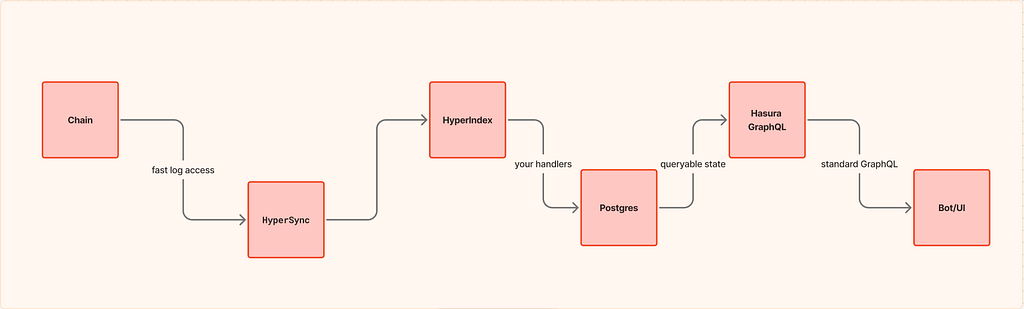
Envio explicitly positions HyperIndex as the indexing framework that turns events into structured DB + GraphQL APIs, and HyperSync as the fast data engine beneath it.
Their local development workflow uses Hasura as the GraphQL console/UI.
Step zero: scaffold the project
Envio’s own tutorials use pnpx envio init, then generate the three core files: config.yaml, schema.graphql, and src/EventHandlers.*.
They recommend Node.js v22+, pnpm, and Docker Desktop for local runs.
When you start your indexer with pnpm dev, Envio’s tutorial notes it will start Docker containers, set up the database, launch indexing, and open the Hasura GraphQL interface.
config.yaml
This is the “post-subgraph manifest.”
In Envio, project configuration lives in config.yaml, and it defines networks, contracts, and events to index.
Below is an example that indexes ERC‑20 transfers with wildcard mode, and runs across multiple networks (add/remove networks to taste). The core idea is straight from Envio’s wildcard indexing docs: define the Transfer event; enable wildcard in the handler registration; then filter.
Paste this as config.yaml:
https://medium.com/media/24c0177d96de6ebe3c923283cc8c88bd/href
Why unordered_multichain_mode?
Envio documents that unordered mode processes events as soon as they’re available per chain (still ordered within a chain), avoids waiting for the slowest chain, and is recommended for most apps when cross-chain ordering doesn’t matter.
They also describe the resilience angle: one laggy chain shouldn’t freeze the rest.
schema.graphql
Envio’s docs are explicit: every entity type in schema.graphql maps to a database table, and HyperIndex generates a GraphQL API from them.
Keep the schema small and purposeful. For trader-grade UX, you usually want:
a raw “Transfer” row (for the feed)an “AddressStats” row (for leaderboards and netflow summaries)
Paste this as schema.graphql:
https://medium.com/media/83bfa13c756b016641d48cbb0b3a31e3/href
A couple small but important notes:
Envio requires entities to have a unique id, and supports scalars like BigInt for Solidity-sized integers.You’ll want chain‑namespaced IDs for multichain to avoid collisions; Envio even calls this out as a best practice (“append the chain ID to entity IDs”).
src/EventHandlers.ts
Envio handlers are where “raw logs become app state.”
Their handler docs show the core patterns you’ll use:
context.Entity.get(…) / getOrCreate(…)context.Entity.set(…) to write updates
Their wildcard indexing doc shows the exact shape of a wildcard transfer handler (including { wildcard: true }) and then topic filtering with eventFilters.
Paste this as src/EventHandlers.ts:
https://medium.com/media/0c98f0f134fe7ce9a00aa73f4669a250/href
Why this is “post-subgraph era” code:
It’s small enough that you actually own it.It’s explicit about what you store and why.It treats multichain and address collisions as first-class concerns.
Optional upgrade: topic filtering to reduce load even more
Wildcard indexing can pull a massive event volume across big chains. Envio’s docs explicitly warn that indexing all ERC‑20 transfers is “a lot of events,” and recommend topic filtering using eventFilters on indexed params (like from and to).
In practice, that means you can push filtering down closer to the log-selection layer, not just in your handler.
Query it like a trader
Locally, Envio uses Hasura as the GraphQL engine + UI, and documents that when running locally it’s available at http://localhost:8080 with password testing.
Here are two queries worth including.
Feed query: latest transfers involving watchlist
https://medium.com/media/5e2a8b42cf4d0b24eb2b2ff290449832/href
Leaderboard query: who’s receiving the most (in raw units)
https://medium.com/media/808ff788cbac2dc019df3d308210dabb/href
Alchemy’s shutdown taught the ecosystem a pretty clean lesson: an indexer endpoint is not “just infra.” It’s product surface area.
Envio’s docs (and the way HyperIndex is structured) map well onto what teams now want:
a clear config.yaml that defines the indexing scopea schema.graphql that becomes real DB tables + a generated GraphQL APIhandler code that looks like normal backend code (retrieve/update entities with getOrCreate and set)multichain that’s not a pile of duplicated deploymentsevent-volume controls like wildcard + topic filtering for “trader feed” workloadsdeployment that fits modern Git workflows (Envio Cloud describes a git-based flow like Vercel)
The biggest lesson from the “subgraph era” isn’t that subgraphs were bad , it’s that Web3 outgrew them.
What worked for single-chain apps and simple queries doesn’t hold up when you’re dealing with multichain state, real-time analytics, and production-grade backends.
Builders today don’t just need indexed data.
They need fast backfills, unified schemas, and systems they actually control.
That’s the real shift.
We’re moving from “querying blockchain data” → to “designing data systems on top of blockchains.”
And once you see indexers as part of your backend — not just a tool — your entire architecture changes.
So the next time you reach for a subgraph, ask yourself:
👉 Am I just querying data… or building a system?
Because in this post-subgraph world, that difference matters.
#web3 #blockchain #cryptodev #defi #programming #softwareengineering #opensource
After Subgraphs: Rethinking Web3 Data Infrastructure with Envio was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.