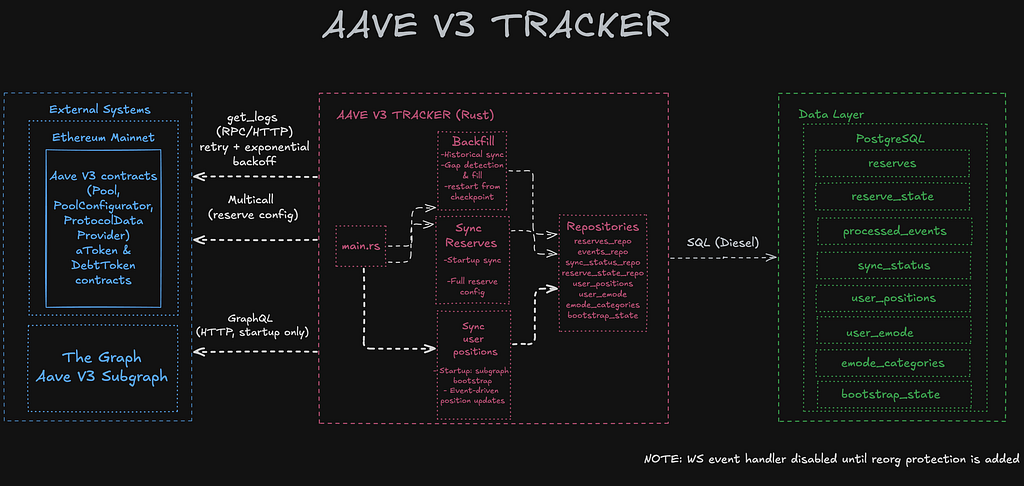
I spent the last few months building an Aave V3 indexer in Rust. It reads on-chain events from Ethereum Mainnet and writes protocol state into PostgreSQL -reserve configs, interest rate data, user supply/borrow positions, and eMode categories. The stack is Rust with Tokio for async, Alloy for Ethereum interaction, and Diesel for PostgreSQL.
It sounded straightforward at first: listen to events, decode them, write to a database. In practice, almost every assumption I started with turned out to be wrong or incomplete.
1. Large Numbers Need the Right Type
Solidity uses integers for everything -1.5 ETH is 1500000000000000000 on-chain. Aave’s internal math goes further: it uses RAY (10^27) as a fixed-point base, so an intermediate calculation like amount × RAY, where the amount is already 10^18, produces 10^45. Rust’s u128 maxes out at roughly 10^38, so it overflows. Aave itself uses uint256 in Solidity, and the Rust equivalent is Alloy’s U256.
That handles the math, but U256 isn’t a storage type. For values that stay large -balances, liquidity indices, supply caps- BigDecimal maps cleanly to PostgreSQL’s NUMERIC and doesn’t lose precision.
2. Self-Healing: What Happens When an Unknown Reserve Shows Up
During backfill, maybe I missed an event, and I get a ReserveDataUpdated event for a reserve that didn’t exist in the database yet. This can happen because we may have missed the ReserveInitialized event for that reserve.
The question was: what should the indexer do? Skipping the event because we don’t have that reserve is completely the wrong way to go, because apparently, we missed something. Throwing an error and stopping means that a single edge case blocks the entire system, which does not make sense.
I saw it as an opportunity to fix missing data, and I went with self-healing: if an event references a reserve that’s not in the database, the indexer fetches that reserve’s full config from the chain via RPC, inserts it, and then continues processing normally. It prevents a missing reserve from blocking the entire backfill.
Code is shown below:
if !exists {
warn!(
asset = %asset_str,
block = block_number,
“Reserve not found in DB — fetching from RPC”
);
process_reserve(pool, &provider, asset_addr, data_provider_addr, pool_addr, Some(block_number as u64))
.await
.wrap_err_with(|| {
format!(
“Self-healing: failed to fetch reserve {} from RPC”,
asset_str
)
})?;
}
The same pattern applies to eMode categories -if an event references a category that doesn’t exist locally, the indexer pulls the full category definition from the chain before continuing. The idea is simple: never stop, never lose data, and recover automatically when possible.
3. Reorg, WebSocket, and a Deliberate Tradeoff
Ethereum can reorganize its recent history, and any events you indexed from those discarded blocks may now be invalid in a reorg -but they’re already in your database. So, processing events in real time with WebSocket is not acceptable. Because without reorg handling, a reorganization would leave stale data in the database with no way to detect or fix it.
Instead of implementing full reorg detection and rollback -which is a significant undertaking on its own- I made a deliberate tradeoff: disable WebSocket entirely and only write data through HTTP-based backfill with a 20-block confirmation delay. On Mainnet, 20 blocks are roughly 4 minutes. At that depth, a reorganization is highly unlikely. Real-time data is sacrificed, but correctness is guaranteed -and for my indexer, correctness matters more than latency.
4. Multi-RPC Failover
RPC providers go down, hit rate limits, or return server errors -and when your indexer depends on a single provider, any of these stops everything.
The indexer sticks with one until it starts failing. If a chunk fails and the error looks like a rate limit, timeout, or server error, the provider rotates automatically to the next one. No manual intervention, no downtime.
5. Cold Start: Subgraph Bootstrap + Event Replay
When you start an indexer from scratch, you need a historical state. There are two obvious approaches: replay every event since Aave V3’s deployment, or pull the current state from an external source like The Graph.
Replaying from the beginning is complete but extremely slow -Aave V3 on Ethereum has millions of events. Relying entirely on a subgraph is fast but means trusting an external source for accuracy, and subgraphs can have their own indexing issues.
I combined both: seed user positions from the subgraph at a recent block height, then switched to event replay from that block forward. The subgraph gives you speed for the initial load, and event replay gives you accuracy going forward.
I chose this approach because replaying millions of blocks is resource-intensive and time-consuming. But more importantly, I wanted to make sure my event processing and calculations were actually correct before committing to a full historical sync. If there’s an inaccuracy in how events are processed, waiting for millions of blocks to sync just to discover a bug at the end would be a waste of time.
Also, starting from a recent snapshot let me improve the design much faster -and instead of spending time waiting for a full sync, I could focus on the other parts of the system, which turned out to be much more instructive. It was a deliberate tradeoff for my own learning process.
The tradeoff is real, though: the quality of your starting state depends entirely on the external source. Any inaccuracy in the subgraph’s data propagates into every subsequent position update. I noticed some inconsistencies in practice, which is why the project’s README lists this as a known limitation.
6. Event Replay Safety and Idempotency
If the indexer crashes while processing a chunk of events, that chunk gets retried on restart. Without safeguards, events can be processed twice -and for events like Mint or Burn, that means double-counting a user’s balance or incorrectly reducing it.
The fix is deduplication: every event on Ethereum can be uniquely identified by its transaction hash and log index -log index is needed because a single transaction can emit multiple events. Before processing any event, the indexer records this pair. If the same pair appears again during a retry, it is skipped.
This makes the event handler idempotent. You can replay the same block range as many times as you want. If an event has already been processed, running again won’t change the database state.
Combined with checkpoint recovery -saving progress per block range so the indexer resumes from where it left off- this gives you crash safety. The indexer can be stopped and restarted at any point without data corruption or double-counting.
7. Position Tracking: Harder Than It Looks
I initially assumed the Pool contract was the single source of truth for user balances. But because aTokens are real ERC-20 tokens, users can transfer them directly to other addresses without going through the Pool.
This means watching Pool events alone isn’t enough -the Pool doesn’t see direct aToken transfers between users. To keep positions accurate, you also need to track events on each individual token contract.
On top of that, the balances themselves aren’t straightforward. Aave doesn’t store actual token amounts -it stores “scaled” values. The relationship looks like this:
actualBalance = scaledBalance × liquidityIndex / RAY
The liquidity index grows over time as interest accrues, which means every user’s real balance increases passively -without any individual events being emitted.
Not all token events report values the same way. I track BalanceTransfer -Aave’s custom event for aToken transfers between users- rather than the standard ERC-20 Transfer event. A single user-to-user transfer can emit multiple Transfer events: one for the actual move, and up to two more from address(0) for interest that accrued on each side since their last interaction. All of them carry actual amounts, so you’d need to fetch the index separately and call rayDiv on each one. BalanceTransfer sidesteps all of this: it emits exactly once per transfer, includes the scaled amount directly alongside the index, and is much simpler to track and compute with.
Mint and Burn are more involved. Both events carry a balanceIncrease field -the interest that accrued on the user’s position since their last interaction. For Mint, the emitted value is amount + balanceIncrease, so you subtract the accrued interest before dividing: (value – balanceIncrease).rayDiv(index). For Burn, the emitted value is amount – balanceIncrease, so you add it back first: (value + balanceIncrease).rayDiv(index).
Due to those calculations, you may have wei drift per event. You can even see this on-chain. Here’s an example transaction where the Supply event and the Mint event in the same transaction report values that differ by 1 wei due to Aave’s internal fixed-point rounding (rayDiv/rayMul). This ±1 wei drift is a protocol-level property, not a bug -but it means the indexer has to expect and handle small discrepancies in every calculation.
What’s Still Missing
The project is far from done. Reorg handling isn’t implemented -the 20 block delay is a workaround, not a solution. Asset prices aren’t tracked yet, which means health factor calculation isn’t possible. The Pool and PoolConfigurator addresses are hardcoded, so if Aave governance deploys new contracts, the indexer won’t notice.
There’s also the subgraph accuracy issue I mentioned: any error in the bootstrapped data carries forward into all subsequent updates.
Most of what I learned from this project didn’t come from the Rust code itself -it came from understanding how the protocol actually works and why simple assumptions break quickly when you’re dealing with real on-chain data.
This is an actively evolving project -code and design decisions may change as I learn more.
More details and known tradeoffs in the Repo.
Designing an Aave V3 Indexer: Challenges and Insights was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.