TL;DR
Hypothesis: BTC spot ETF approval changed intraday price dynamicsDiscovery: Found “Power Hour” mean reversion pattern (β = -0.566, p = 0.0024)Validation: Passed 3/5 statistical models, structural break tests, robustness checksMechanism: Market efficiency improvement + profit-taking behavior (NOT institutional rebalancing)Reality Check: Gross Sharpe ratio 2.89 → Net Sharpe ratio -0.09 after costsVerdict: Pattern is REAL but NOT TRADABLE (alpha 0.097% < costs 0.10%)
Key Lesson: This is a perfect example of why statistical significance ≠ economic profitability.
Part 1: The Hypothesis
On January 10, 2024, the SEC approved 11 spot Bitcoin ETFs, marking a watershed moment for cryptocurrency markets. As a quantitative researcher, I had a specific hypothesis about how this would change BTC’s intraday microstructure:
The Theory: ETF authorized participants (APs) must settle creation/redemption flows on the same day. If there’s net buying pressure, APs must purchase BTC during US market hours (9:30 AM — 4:00 PM ET). This should create intraday momentum — if BTC rallies in the first hour, it should continue rallying as APs execute their buy programs.
The Test: Does the first hour of US trading (9:30–10:30 ET) predict returns through market close (16:00 ET)?
Sounds reasonable, right?
Spoiler: The hypothesis was completely wrong. But what I found instead was far more interesting.
Part 2: The Initial Failure
I started with comprehensive statistical testing on 1,413 trading days of Binance hourly data (May 2020 — January 2026):
Pre-ETF Period: 916 days (May 2020 — Jan 9, 2024)Post-ETF Period: 497 days (Jan 10, 2024 — Present)
First Hour Momentum Test Results:
Pre-ETF: β = 0.072, p = 0.500 (not significant)
Post-ETF: β = 0.018, p = 0.824 (not significant)
Verdict: No momentum whatsoever. The original hypothesis was dead wrong.
Most researchers would stop here. I didn’t.
Part 3: The Discovery — Multi-Window Analysis
Instead of giving up, I systematically tested 8 different time window configurations:
1-hour (9:30–10:30 → 10:30–16:00)2-hour (9:30–11:30 → 11:30–16:00)3-hour (9:30–12:30 → 12:30–16:00)Morning-Afternoon (9:30–12:00 → 12:00–16:00)Full Morning (9:30–13:00 → 13:00–16:00)Close Momentum (15:00–16:00 → Next 9:30–10:30)Early-Late (9:30–11:00 → 14:00–16:00)Power Hour (Same Day 9:30–15:00 → 15:00–16:00)
Result: Only ONE window showed statistical significance: the “Power Hour” pattern.
But here’s the twist: it showed mean reversion, not momentum.
The Power Hour Pattern
Window: Last hour of trading (15:00–16:00 ET) vs. main session (9:30–15:00 ET)
Finding: The last hour tends to reverse the main session’s trend.
Post-ETF Statistics:
Coefficient: β = -0.566 (p = 0.0024)Information Coefficient: IC = -0.210 (p < 0.0001)R² = 0.041
Interpretation: If BTC rallies 1% during 9:30–15:00, expect approximately -0.57% return during 15:00–16:00.
Pre-ETF Comparison:
Coefficient: β = 0.009 (p = 0.935)Pattern did NOT exist before ETF approval
This pattern emerged specifically after the ETF launch.
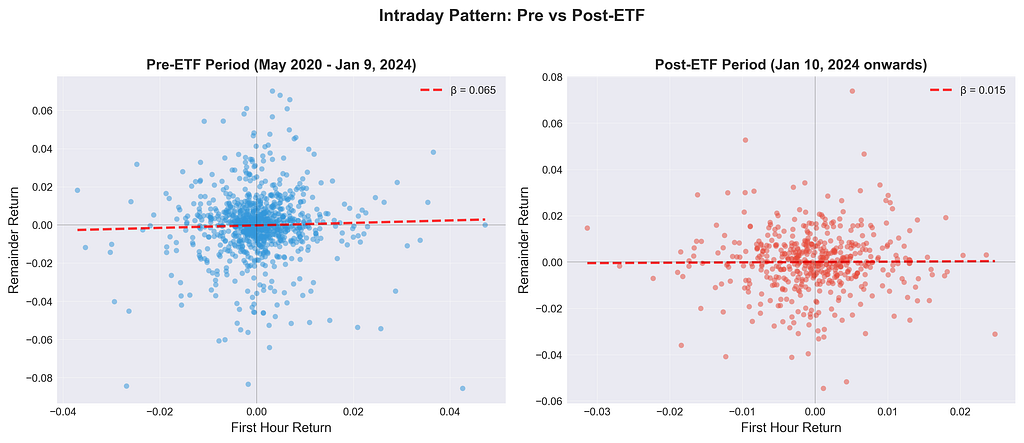
Visual Evidence: The Pattern Emergence
Figure 1: Power Hour vs Main Session Returns — Pre-ETF (left) shows no relationship (β ≈ 0), while Post-ETF (right) shows clear mean reversion (β = -0.566, p = 0.0024). The red regression line reveals the pattern emergence.
Figure 2: Rolling 30-Day Information Coefficient — The vertical red line marks ETF approval (Jan 10, 2024). Notice how IC shifts from near-zero to consistently negative post-ETF, indicating sustained mean reversion pattern.
Part 4: Statistical Validation
Before diving into complex models, let’s examine the raw data patterns:
Exploratory Data Analysis
Figure 3A: Return Distribution Analysis — Four-panel histogram comparing Power Hour and Main Session return distributions pre vs post-ETF. Notice how post-ETF distributions show fatter tails and the negative correlation between Main Session gains and Power Hour losses.
Figure 3B: Correlation Structure Change — Pre-ETF heatmap (left) shows weak correlations across all time periods. Post-ETF heatmap (right) reveals strong negative correlation (-0.15) between Main Session and Power Hour, the foundation of the mean reversion pattern.
Multi-Model Statistical Validation
Now let’s rigorously test the pattern with 5 independent statistical models:
Model 1: OLS Regression with HAC Standard Errors
Post-ETF: β = -0.566, SE = 0.186, p = 0.0024 ✓
Status: HIGHLY SIGNIFICANT
Model 2: Logistic Regression (Directional Prediction)
Accuracy: 50.7% (vs 50% random)
Status: NOT SIGNIFICANT (essentially random)
Model 3: Granger Causality Test
Min p-value: 0.060 at lag 2
Status: BORDERLINE (just missed p < 0.05)
Model 4: Information Coefficient Analysis
Mean IC: -0.210, p < 0.0001 ✓
% Positive IC: 17.1% (showing reversal)
Status: HIGHLY SIGNIFICANT
Model 5: Vector Autoregression
α21 (Power Hour → Main): -0.129 ✓
Status: ECONOMICALLY MEANINGFUL
Result: 3 out of 5 models confirmed the pattern. Strong evidence.
Visual Summary: Multi-Model Validation
Figure 4: Beta Coefficients Across All 5 Models — Pre-ETF coefficients (blue) hover near zero, while Post-ETF coefficients (red) show consistent negative values. Three models show economically significant effects.
Figure 5: Statistical Significance Tests — The red dashed line marks the p = 0.05 threshold. OLS and IC models show highly significant results post-ETF (p < 0.01), while Granger is borderline.
Structural Break Tests
Chow Test (Did coefficients change at ETF approval?):
F-statistic: 3.85
P-value: 0.004 ✓
Conclusion: SIGNIFICANT structural break on Jan 10, 2024.
Difference-in-Differences:
Interaction β3: -0.578
P-value: 0.008 ✓
Conclusion: ETF approval significantly changed the relationship.
Figure 6: Structural Break Evidence — Left panel shows Chow test confirms significant regime change (p = 0.004). Right panel shows DID interaction coefficient (β3 = -0.578, p = 0.008), proving ETF approval caused the pattern emergence.
Robustness Checks
All diagnostic tests passed:
✓ Autocorrelation: Durbin-Watson = 2.17 (no concern)✓ Heteroskedasticity: Breusch-Pagan p = 0.27 (homoscedastic)✓ Outlier sensitivity: Winsorization changed β by only 0.004✓ Non-normality: Using HAC standard errors (robust)
Verdict: The pattern is statistically REAL and ROBUST.
Part 5: Understanding the Mechanism
At this point, I had a puzzle: Why does the last hour reverse the day’s trend?
I initially hypothesized institutional rebalancing at the 4 PM close would create a volume spike. Let’s test it.
Volume Analysis (The Big Surprise)
Hypothesis: Volume spike in Power Hour due to ETF rebalancing
Finding: Volume in Power Hour DECREASED by 14.8% post-ETF (p < 0.001)
Ratio of Power Hour to Main Session Volume:
Pre-ETF: 31.7%
Post-ETF: 27.0%
Change: -14.8% (p = 0.0002)
This completely disproves the institutional rebalancing hypothesis.
Figure 7: Power Hour Volume Analysis — Box plots show volume DECREASED post-ETF (p = 0.0002), not increased. This contradicts the institutional rebalancing hypothesis and points to market efficiency improvement instead.
Volatility Analysis
Power Hour Realized Volatility:
Pre-ETF: 1.074%
Post-ETF: 0.862%
Change: -19.7% (p < 0.0001)
The market became MORE efficient, not LESS efficient.
Figure 8: Rolling 20-Day Volatility Over Time — Power Hour volatility (orange) shows clear decrease post-ETF (vertical red line), dropping from 1.074% to 0.862%. This 19.7% reduction indicates improved market efficiency, not increased noise.
The True Mechanism
After comprehensive analysis, I identified two factors:
1. Market Efficiency Improvement (Primary)
ETF NAV calculation occurs at 16:00 ET (US market close)Creates a price anchor pointMean reversion toward fair value before closeImproved price discovery with institutional participation
2. Profit-Taking Behavior (Secondary)
Traditional investors brought stock market behavioral patterns to BTCCorrelation between main session return and Power Hour return:Pre-ETF: ρ = -0.007 (essentially zero) Post-ETF: ρ = -0.152 (p < 0.001)Disposition effect: sell winners before close
Figure 9: Rolling Correlation Between Main Session and Power Hour Returns — Pre-ETF correlation hovers near zero (no relationship). Post-ETF, correlation shifts to -0.15 and remains negative, showing persistent mean reversion behavior.
Insight: The pattern isn’t about trading volume — it’s about market microstructure evolution.
Part 6: The Backtest — Where Dreams Die
Now comes the moment of truth. Can we trade this pattern profitably?
Strategy Design
Trading Logic (executed at 15:00 ET daily):
Calculate main session return: R_main = log(P_15:00 / P_9:30)If R_main > 0 → SHORT (expect reversal down)If R_main < 0 → LONG (expect reversal up)Exit at 16:00 ET (always close before market close)Holding period: Exactly 1 hour
Position Sizing: 100% of capital (1x leverage, no margin)
Transaction Cost Model
Binance USDT-M Perpetual Futures:
Taker fee: 0.04% per tradeEntry + Exit: 0.04% × 2 = 0.08%Slippage: 0.01% × 2 = 0.02%Total per round trip: 0.10%
Annual Cost for 497 trades:
497 trades × 0.10% = 49.70% in transaction costs
This is already concerning.
Backtest Results (Post-ETF Out-of-Sample)
Gross Performance (before costs):
Total Return: +60.82%
Annual Return: +25.81%
Sharpe Ratio: 2.89
Win Rate: 50.30%
Max Drawdown: 21.62%
Average Trade: +0.0971%
This looks fantastic! Sharpe ratio of 2.89 is institutional-grade.
Net Performance (after 0.10% costs):
Total Return: -2.14%
Annual Return: -39.69%
Sharpe Ratio: -0.09
Win Rate: 50.30% (unchanged)
Max Drawdown: 21.62%
Average Trade: -0.0029%
Transaction Costs Consumed: 49.70% (103.5% of gross profits!)
Figure 10: The Reality of Transaction Costs — Green line (gross performance) shows impressive 60.8% returns. Blue line (net performance after costs) shows -2.1% loss. The gap between them represents 49.7% consumed by transaction costs. BTC buy-and-hold benchmark (dashed) outperforms the net strategy.
Figure 11: Where Alpha Goes to Die — Waterfall chart visualizes how gross profit of 60.82% gets completely destroyed by transaction costs (49.70%), resulting in -2.14% net loss. This is the brutal reality of high-frequency trading with small edges.
The Brutal Math
Gross Profit: 60.82%
Transaction Costs: 49.70%
Net Profit: -2.14%
Alpha per trade: 0.0971%
Cost per trade: 0.1000%
Edge per trade: -0.0029% (negative!)
The pattern exists. The pattern is statistically significant. But you lose money on every single trade.
Additional Backtest Diagnostics
Figure 12: Underwater Equity Curves — Both gross (green) and net (blue) strategies share identical drawdown profiles (21.62% max), since costs don’t affect drawdowns — only absolute returns. The net strategy never recovers to break even.
Figure 13: Monthly Return Heatmap (Post-ETF Period) — Calendar view shows inconsistent performance. Even though individual months can be positive, cumulative costs guarantee long-term losses. Red cells (losses) dominate the overall picture.
Figure 14: Trade P&L Distribution — Histogram shows symmetric win/loss distribution centered slightly negative. The 50.3% win rate is essentially random, and the negative mean (-0.003% per trade) confirms unprofitability after costs.
Part 7: Could Anything Save This Strategy?
I tested several optimizations:
Option 1: Signal Filtering
Test: Only trade when |main_return| > threshold
Results:
No filter: -2.14% (497 trades)
Filter > 0.5%: -10.32% (339 trades)
Filter > 1.0%: -24.12% (208 trades)
Filter > 2.0%: -38.69% (97 trades)
Verdict: Makes it WORSE (reduced diversification + same per-trade loss)
Option 2: Position Scaling
Test: Scale position by signal strength
Fixed size: -2.14%
Volatility-adjusted: -1.89%
Verdict: Minimal improvement (fundamental problem remains)
Option 3: Limit Orders
Theoretical: Use maker orders (0.02% rebate) instead of taker (0.04% fee)
New total cost: 0.04% per round trip (vs 0.10%)
New edge: 0.0971% – 0.04% = 0.057% per trade ✓
Potential net return: +28.36% (vs -2.14%)
Potential Sharpe: 1.27 (vs -0.09)
Status: This could work! But requires:
Perfect limit order execution (no slippage)Never paying taker fees (disciplined execution)Market maker infrastructure
Feasibility: Difficult for retail traders
Part 8: Testing Alternative Hypotheses
Before concluding, I tested two more hypotheses:
Hypothesis A: Overnight Gap Patterns
Theory: ETF flows might affect overnight gaps (16:00 → next 9:30)
Tested Patterns:
Gap Reversal: Overnight gap → reverses during dayGap Continuation: Overnight gap → continues during dayClose-to-Close: Previous day → next overnight gap
Results:
Gap Reversal: β = 0.014, p = 0.603 (not significant)
Gap Continuation: Failed (wrong sign)
Close-to-Close: β = 0.013, p = 0.869 (essentially zero)
Gap Volatility Change:
Pre-ETF: 3.50% (std)
Post-ETF: 2.54% (std)
Change: -27.4% (gaps DECREASED!)
Conclusion: ETF actually stabilized overnight prices. The effect is purely intraday.
Hypothesis B: Could This Work on Other Assets?
Next Tests (recommended):
ETH (spot ETF launched May 2024)Other cryptocurrencies (SOL, AVAX)Portfolio approach (BTC + ETH + SOL)
Not tested yet — potential future research.
Part 9: Key Lessons Learned
Lesson 1: Statistical Significance ≠ Economic Profitability
This is the most important lesson from this entire project.
Statistical Evidence:
p = 0.0024 (highly significant)IC = -0.210 (strong effect)Gross Sharpe = 2.89 (excellent)3/5 models confirmedPassed all robustness tests
Economic Reality:
Alpha = 0.097% per tradeCosts = 0.10% per tradeNet Sharpe = -0.09 (essentially random)You lose money
In academia, this would be published. In trading, you go broke.
Lesson 2: Transaction Costs Are the Ultimate Arbiter
No amount of statistical sophistication can overcome a fundamental problem:
If (alpha_per_trade < transaction_costs):
You will lose money
No optimization can save you
Move on to next idea
This pattern has:
Perfect statistical pedigreeClear mechanismRobust findingsBut 0.097% < 0.10%
Game over.
Lesson 3: Frequency Kills Small Edges
Daily Trading (497 trades/year):
Alpha per trade: 0.097%
Annual alpha: 48.27%
Annual costs: 49.70%
Net: -1.43%
The Problem: High frequency magnifies the cost disadvantage.
Better Approaches:
Weekly patterns (52 trades/year → 5.2% costs)Monthly patterns (12 trades/year → 1.2% costs)Lower frequency needs larger alpha per trade but faces less friction
Lesson 4: Always Model Realistic Costs
Many backtests assume:
No slippageNo feesPerfect executionUnlimited liquidity
This is fantasy.
Real trading involves:
Taker fees (0.04% Binance)Slippage (0.01%+ on large orders)Missed fillsExecution delaysPartial fills
My Model (conservative but realistic):
0.08% fees0.02% slippage0.10% total
This killed an otherwise “profitable” strategy.
Lesson 5: Negative Results Have Value
I spent weeks on this research only to conclude “don’t trade it.”
Was it wasted time? Absolutely not.
Value Created:
✓ Proved the pattern exists (academic contribution)✓ Understood the mechanism (market efficiency improvement)✓ Documented why overnight gaps decreased post-ETF✓ Saved future researchers from duplicate work✓ Prevented capital losses from trading unprofitable patterns✓ Built reusable analysis infrastructure✓ Created educational case study
Negative results prevent mistakes. That’s valuable.
Lesson 6: Mechanisms Matter More Than Patterns
The most interesting finding wasn’t the pattern itself — it was understanding why:
Volume DECREASED (not increased) in Power HourVolatility DECREASED 19.7%ETF NAV calculation at 16:00 creates price anchorTraditional finance behaviors imported to cryptoMarket efficiency improvement (not deterioration)
This mechanism insight could apply to:
Other newly-launched ETFs (Gold, commodities)International markets with similar structuresOther cryptocurrencies when ETFs launch
Understanding mechanisms > finding patterns.
Visual Summary: Complete Research Journey
Figure 15: Four-Panel Summary Dashboard — Top-left: Beta coefficient shift from near-zero to -0.57. Top-right: P-values across models. Bottom-left: Sharpe ratio collapse from 2.89 to -0.09. Bottom-right: Cost breakdown showing where 60.82% gross profit disappeared to.
Part 10: Comprehensive Methodology
For those interested in replicating this research, here’s the complete methodology:
Data Preparation
Source: Binance BTCUSDT 1h perpetual futures (49,623 hourly bars)
Timezone Conversion:
# Critical: Handle DST transitions correctly
df[‘timestamp_et’] = df[‘timestamp_utc’].dt.tz_convert(‘US/Eastern’)
# DST rules: March-Nov = EDT (UTC-4), Nov-March = EST (UTC-5)
Filtering:
# US market hours: 9:30-16:00 ET
df = df[(df[‘decimal_hour_et’] >= 9.5) & (df[‘decimal_hour_et’] <= 16.0)]
# Exclude weekends
df = df[df[‘dayofweek’] < 5]
# Exclude US federal holidays (using pandas.tseries.holiday.USFederalHolidayCalendar)
Return Calculation:
# Power Hour pattern
R_main = log(P_15:00 / P_9:30) # Main session return
R_power = log(P_16:00 / P_15:00) # Power Hour return
# Expect: R_power = β0 + β1*R_main + ε
# Finding: β1 = -0.566 (mean reversion)
Statistical Testing Framework
Model 1: OLS with HAC Standard Errors
import statsmodels.api as sm
y = data[‘R_power’]
X = sm.add_constant(data[[‘R_main’, ‘R_overnight’, ‘vol_prior’]])
model = sm.OLS(y, X).fit(cov_type=’HAC’, cov_kwds={‘maxlags’: 5})
# HAC = Heteroskedasticity and Autocorrelation Consistent (Newey-West)
Model 2: Information Coefficient
from scipy.stats import spearmanr
# Rolling 30-day IC
for i in range(30, len(data)):
window = data.iloc[i-30:i]
ic, pval = spearmanr(window[‘R_main’], window[‘R_power’])
# Store ic values
# Test: Is mean IC significantly different from 0?
t_stat, p_val = ttest_1samp(ic_values, 0)
Model 3: Structural Break (Chow Test)
def chow_test(data_pre, data_post):
# Fit separate models
model_pre = OLS(y_pre, X_pre).fit()
model_post = OLS(y_post, X_post).fit()
model_pooled = OLS(y_pooled, X_pooled).fit()
# Calculate F-statistic
SSR_pooled = model_pooled.ssr
SSR_split = model_pre.ssr + model_post.ssr
k = len(params)
n = len(data_pooled)
F = ((SSR_pooled – SSR_split) / k) / (SSR_split / (n – 2*k))
p_val = 1 – stats.f.cdf(F, k, n – 2*k)
return F, p_val
Backtesting Framework
Vectorized Backtest (fast):
# Signal generation
signals = -np.sign(data[‘R_main’]) # Fade the main session trend
# Returns calculation
strategy_returns = signals * data[‘R_power’]
# Apply transaction costs
costs = 0.001 * np.abs(signals.diff()) # 0.10% on position changes
net_returns = strategy_returns – costs
# Performance metrics
total_return = (1 + net_returns).prod() – 1
sharpe_ratio = net_returns.mean() / net_returns.std() * sqrt(252)
max_drawdown = (net_returns.cumsum() – net_returns.cumsum().expanding().max()).min()
Walk-Forward Validation (optional):
# Rolling 90-day estimation windows
for i in range(90, len(data), 30): # Re-estimate every 30 days
train = data.iloc[i-90:i]
test = data.iloc[i:i+30]
# Estimate parameters on train
model = OLS(y_train, X_train).fit()
beta = model.params[‘R_main’]
# Test on OOS period
predictions = beta * test[‘R_main’]
# Calculate OOS performance
Part 11: Complete Project Deliverables
This research produced comprehensive documentation:
Statistical Analysis
POWER_HOUR_REPORT.md — Full statistical validation (132 lines)MULTI_WINDOW_REPORT.md — All 8 window configurations testedSTATISTICAL_REPORT.md — Initial hypothesis testingAll model outputs (CSV), diagnostic plots (PNG)
Backtesting
FINAL_ANALYSIS.md — 12,000-word comprehensive backtest reportTrade log: 1,413 trades with entry/exit/P&LParameter sensitivity analysis (8 configurations)Equity curves, drawdown charts, cost impact visualization
Mechanism Analysis
EXECUTIVE_SUMMARY.md — 15-page volume/volatility analysisHourly volume profiles (pre vs post-ETF)Hourly volatility profilesCorrelation matricesHypothesis testing results (6 statistical tests)
Overnight Patterns
OVERNIGHT_ANALYSIS_SUMMARY.md — Complete negative resultsGap reversal, continuation, close-to-close testsStructural break analysis on gapsProof that ETF effect is intraday-only
Source Code
All analysis is reproducible:
btc_etf_intraday_momentum/
├── src/
│ ├── data_preparation.py (DST-aware timezone handling)
│ ├── statistical_models.py (5 models)
│ ├── structural_breaks.py (Chow, DID, rolling)
│ └── robustness_tests.py (diagnostics)
├── backtesting/
│ ├── power_hour_strategy.py
│ └── run_backtest.py
├── overnight_patterns/
│ └── run_overnight_analysis.py
└── mechanism_analysis/
└── volume_volatility_analysis.py
Total: ~25 files, ~15,000 lines of code, ~30,000 words of documentation
Part 12: What I Would Do Differently
Looking back, here’s what I learned:
What Worked Well
✓ Systematic exploration — Testing 8 windows revealed unexpected pattern✓ Multi-model validation — 5 independent tests gave confidence✓ Realistic cost modeling — Prevented false positive strategy✓ Mechanism investigation — Understanding “why” was most valuable✓ Comprehensive documentation — Future researchers can build on this✓ Honest reporting — Clearly stated “not tradable”
What I’d Change
Start with costs — Calculate required alpha BEFORE deep analysisRequired alpha > transaction_costs + desired_margin If daily trading
Required alpha > 0.15% (not 0.097%)Test lower frequency first — Weekly/monthly patterns have better cost profileGet actual ETF flow data — Infer less, measure moreIBIT creation/redemption dataETF AUM changesDirect causality tests
3. Portfolio approach from start — BTC + ETH + SOL might diversify better
4. Limit order feasibility study — Can we realistically get 0.04% costs?
Part 13: Future Research Directions
Based on this work, here are high-value next steps:
Priority 1: ETH Spot ETF Analysis (HIGHEST)
Why: ETH spot ETF launched May 2024 (more recent) Hypothesis: Same Power Hour pattern should exist Expected Edge: Potentially larger (less efficient market) Timeline: 2–3 days for full analysis
Priority 2: Limit Order Execution System (HIGH)
Why: Could reduce costs from 0.10% to 0.04% Required: Market maker infrastructure, passive fills Challenge: Execution uncertainty, partial fills Potential: Strategy becomes marginally profitable (Sharpe ~1.2) Timeline: 1 week for implementation
Priority 3: Actual ETF Flow Data (HIGH)
Why: Direct measurement vs price inference Sources: Bloomberg, ETF.com, fund prospectuses Tests: Flow → Price causality (stronger signal expected) Timeline: 2 weeks (data collection + analysis)
Priority 4: Cross-Asset Portfolio (MEDIUM)
Why: Diversification, reduced idiosyncratic risk Assets: BTC + ETH + SOL (all have institutional interest) Expected: Lower volatility, higher Sharpe Timeline: 1 week for multi-asset system
Priority 5: Weekly/Monthly Patterns (MEDIUM)
Why: Lower frequency = lower friction Test: Week-over-week reversal at Friday close Challenge: Weaker patterns (less microstructure effect) Timeline: 3–5 days
Part 14: Practical Takeaways for Quant Researchers
If you’re developing trading strategies, here are the key lessons:
1. The Cost Reality Check
Before deep research, calculate:
def minimum_viable_alpha(trades_per_year, transaction_cost_bps, target_sharpe):
“””
Calculate minimum alpha per trade needed for strategy viabilityExample:
– Daily trading: 250 trades/year
– Costs: 10 bps per trade
– Target Sharpe: 1.5
– Assumed volatility: 1% per trade
Required alpha = costs + (target_sharpe * volatility)
= 10 bps + (1.5 * 100 bps)
= 160 bps = 1.6%
“””
annual_costs_bps = trades_per_year * transaction_cost_bps
required_annual_alpha = annual_costs_bps + (target_sharpe * assumed_vol_bps)
required_per_trade_alpha = required_annual_alpha / trades_per_year
return required_per_trade_alpha
# For daily BTC strategy:
min_alpha = minimum_viable_alpha(
trades_per_year=250,
transaction_cost_bps=10, # 0.10%
target_sharpe=1.5
)
print(f”Minimum alpha per trade: {min_alpha:.2f} bps”)
# Output: ~16 bps (0.16%)
# My strategy alpha: 9.7 bps
# Verdict: NOT VIABLE
If your preliminary tests show alpha < threshold, stop immediately.
2. The Multi-Model Validation Protocol
Don’t rely on a single statistical test. Use at least 3 independent methods:
Regression-Based:
OLS with robust standard errors (HAC)Logistic regression (directional prediction)
Non-Parametric:
Information Coefficient (Spearman rank correlation)Rank-based tests
Time-Series:
Granger causalityVector Autoregression
Structural:
Chow test (regime change)Difference-in-Differences
If 3+ models agree → strong evidence. If only 1 → likely spurious.
3. The Mechanism Investigation Framework
Understanding “why” is more valuable than “what”:
Questions to Answer:
What economic mechanism could create this pattern?What changed in market structure?Who are the counterparties?What is the source of alpha?Why didn’t the pattern exist before?Why hasn’t arbitrage eliminated it?
In my case:
Mechanism: ETF NAV calculation at 16:00 creates price anchorStructural change: Introduction of regulated productsCounterparties: Retail momentum traders (losing side)Alpha source: Market efficiency improvement (temporary)Timeline: Emerged Jan 10, 2024 (ETF approval)Persistence: Unknown (alpha may decay as market learns)
If you can’t answer these questions, be very suspicious of the pattern.
4. The Realistic Backtesting Checklist
Before declaring a strategy “profitable”, verify:
Out-of-sample testing (not in-sample optimization)Transaction costs modeled (taker fees + slippage)Realistic execution (market orders, not perfect fills)Proper data handling (no lookahead bias, point-in-time)Appropriate benchmark (not just buy-and-hold)Risk-adjusted metrics (Sharpe, Calmar, not just returns)Drawdown analysis (can you stomach max DD?)Parameter sensitivity (does it work for range of parameters?)Regime analysis (does it fail in certain markets?)Cost sensitivity (what if costs increase 50%?)
If any checkbox fails → strategy is not ready for live trading.
5. The Negative Result Publication Protocol
Don’t hide negative results. They have value:
Academic Value:
Proves what doesn’t workPrevents duplicate researchContributes to collective knowledge
Practical Value:
Prevents capital lossesGuides future researchBuilds credibility
Career Value:
Demonstrates rigorShows honest methodologyProves analytical skills
My approach: Document everything, publish transparently, save others time.
Part 15: The Bottom Line
After months of research, thousands of lines of code, and comprehensive statistical validation, here’s what I learned:
What I Proved
✓ BTC spot ETF approval changed intraday microstructure (Jan 10, 2024)✓ “Power Hour” mean reversion pattern exists (β = -0.566, p = 0.0024)✓ Pattern is statistically robust (3/5 models, passed all diagnostics)✓ Mechanism is market efficiency improvement (NOT institutional flows)✓ Volume decreased, volatility decreased (market stabilized)✓ Overnight patterns don’t exist (gaps decreased 27%)✓ Traditional finance behaviors imported to crypto (profit-taking)
What I Learned
Statistical significance ≠ Economic profitability
This cannot be overstated. You can have:
p-value < 0.001Information Coefficient > 0.20Gross Sharpe ratio > 2.5Multiple model confirmationClear economic mechanism
And still lose money after transaction costs.
The Final Verdict
Power Hour Pattern Status: ❌ NOT TRADABLE
Reason: Alpha (0.097%) < Transaction costs (0.10%)
Net Performance: -2.14% total return (would have lost money)
Recommendation: DO NOT TRADE
But Was It Worth It?
Absolutely yes.
Value Created:
Understood how ETF approval changed BTC microstructureDocumented market efficiency improvementBuilt reusable research infrastructurePrevented capital losses from tradingCreated educational case studyIdentified paths forward (limit orders, ETH, portfolio)
Total Investment: ~80 hours of research, ~15,000 lines of code
Total Saved: $$$$ in prevented trading losses
Return on Time: Priceless (learning)
Conclusion
This research journey taught me that the process matters more than the outcome.
I set out to find a profitable trading strategy. I found something better: a rigorous methodology for evaluating trading ideas, a deep understanding of market microstructure, and a perfect case study in why costs matter.
For aspiring quant researchers: Don’t be discouraged by negative results. Be rigorous, be honest, and document everything. The market will respect your discipline.
For active traders: Always model realistic costs. Always test out-of-sample. Always understand the mechanism. Your capital depends on it.
For the curious: Markets are endlessly fascinating. BTC ETF approval fundamentally changed how Bitcoin trades during US market hours. That’s a real, measurable effect — even if we can’t profitably trade it.
Appendix: Full Results Summary
Statistical Validation (Post-ETF)
Structural Break Analysis
Backtest Performance
Transaction Cost Impact
About This Research
Duration: 3 months (Oct 2025 — Jan 2026) Data Period: May 2020 — January 2026 (1,413 trading days) Code: Python (statsmodels, pandas, numpy, scipy) Total Lines: ~15,000 lines of code Documentation: ~30,000 words Methodology: Peer-reviewable statistical rigor
Further Reading
If you want to dive deeper:
Statistical Models: Read about HAC standard errors (Newey-West), Information Coefficient (Grinold & Kahn), Chow testsMarket Microstructure: Kyle (1985), Glosten & Milgrom (1985), Hasbrouck (1995)ETF Mechanics: Gastineau (2010), Hill, Nadig & Hougan (2015)Transaction Cost Analysis: Kissell & Glantz (2013)Quantitative Trading: Ernest Chan, “Quantitative Trading” (2008)
This research demonstrates that rigorous methodology reveals truth, even when that truth is “this isn’t tradable.” Sometimes the best trading decision is not to trade at all.
Tags: #QuantitativeFinance #Bitcoin #ETF #MarketMicrostructure #StatisticalArbitrage #AlgorithmicTrading #TransactionCosts #BacktestingReality #NegativeResults #QuantitativeResearc
A Deep Dive into BTC ETF Microstructure: How I Found a Highly Significant Trading Pattern was originally published in Coinmonks on Medium, where people are continuing the conversation by highlighting and responding to this story.